
神经网络和深度学习
什么是神经网络?
我们常常用深度学习这个术语来指训练神经网络的过程。
神经网络就是一个通过深度学习构建出来的大规模函数。可以通过任意x得到一个想要的结果y
ReLU激活函数:全称是Rectified Linear Unit。可以理解成max(0,x),这也是你得到一个这种形状的函数的原因。
神经网络的监督学习
对于一个神经网络的训练过程,人为的设定某些需要的参数和结果。用来导向神经网络的发展方向。
对于图像应用,我们经常在神经网络上使用卷积(Convolutional Neural Network),通常缩写为CNN
对于序列数据,经常使用RNN,一种递归神经网络(Recurrent Neural Network)
从历史经验上看,处理非结构化数据是很难的,与结构化数据比较,让计算机理解非结构化数据很难
神经网络规模和其准确性的关系图
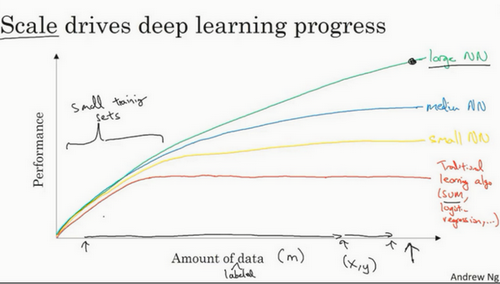
神经网络方面的一个巨大突破是从sigmoid函数转换到一个ReLU函数
通过不断修改算法,代码中的细节。来不断提搞构建高效的神经网络。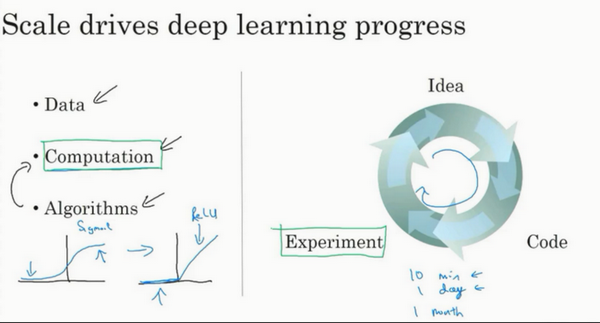
神经网络的编程基础
二分类(Binary Classification)
神经网络的训练过程可以分为前向传播和反向传播两个独立的部分
前向传播就是根据训练集得到代价函数。
反向传播再通过最小化代价函数解的之前的参数。
逻辑回归(Logistic Regression)
逻辑回归(logistic regression)是一个用于二分类(binary classification)的算法
Hypothesis Function(假设函数):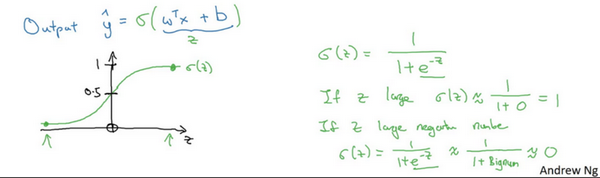
将ReLu函数重新变为sigmoid函数
##逻辑回归的代价函数(Logistic Regression Cost Function)
训练参数w和参数b,你需要定义一个代价函数
逻辑回归的输出函数:
损失函数又叫做误差函数,用来衡量算法的运行情况,Loss function
一般我们用预测值和实际值的平方差或者它们平方差的一半,但是通常在逻辑回归中我们不这么做,因为当我们在学习逻辑回归参数的时候,会发现我们的优化目标不是凸优化,只能找到多个局部最优值,梯度下降法很可能找不到全局最优值,虽然平方差是一个不错的损失函数,但是我们在逻辑回归模型中会定义另外一个损失函数。
逻辑回归可以看做是一个非常小的神经网络
梯度下降法(Gradient Descent)
在你测试集上,通过最小化代价函数(成本函数)J(w,b)来训练的参数w和参数b,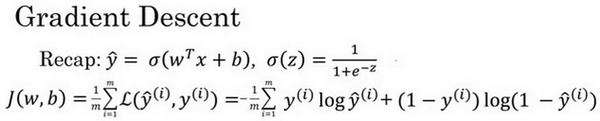
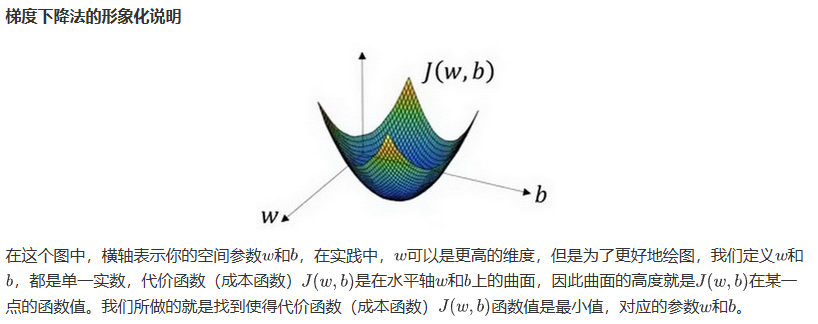
由于逻辑回归函数的代价函数,J(w,b)的特性,我们必须定义其为凸函数。也就是
形如此
如果是非凸,则有多个局部最小值,无法得出结果
梯度下降通过不断迭代参数w,b来找到最小的成本函数J(w,b)
使用计算图求导数(Derivatives with a Computation Graph)
正向或者说从左到右的计算来计算成本函数J,你可能需要优化的函数,然后反向从右到左计算导数
逻辑回归中的梯度下降(Logistic Regression Gradient Descent)
通过计算偏导数来实现逻辑回归的梯度下降算法
1.


一个示例代码流程:
1 | J=0;dw1=0;dw2=0;db=0; |
当你应用深度学习算法,你会发现在代码中显式地使用for循环使你的算法很低效,同时在深度学习领域会有越来越大的数据集。所以能够应用你的算法且没有显式的for循环会是重要的,并且会帮助你适用于更大的数据集。所以这里有一些叫做向量化技术,它可以允许你的代码摆脱这些显式的for循环。
